
Data
Machining & Machine Learning
Predict visual inspection outcome by modeling cutting toolpaths from a CNC mill.
Data ━ 29 Apr, 2021

The team at Human Rights First has a dilemma for discovering the best approach to argue for their client and advocating for better policy. According to U.S. Citizens and Immigration Services, a Freedom Of Information Act (FOIA) request must be submitted to access immigration records. Another source for records are scattered at law offices across the country. This is where the multidisciplinary teams at Lambda School Labs are fit to craft a solution to this decentralized-information problem.
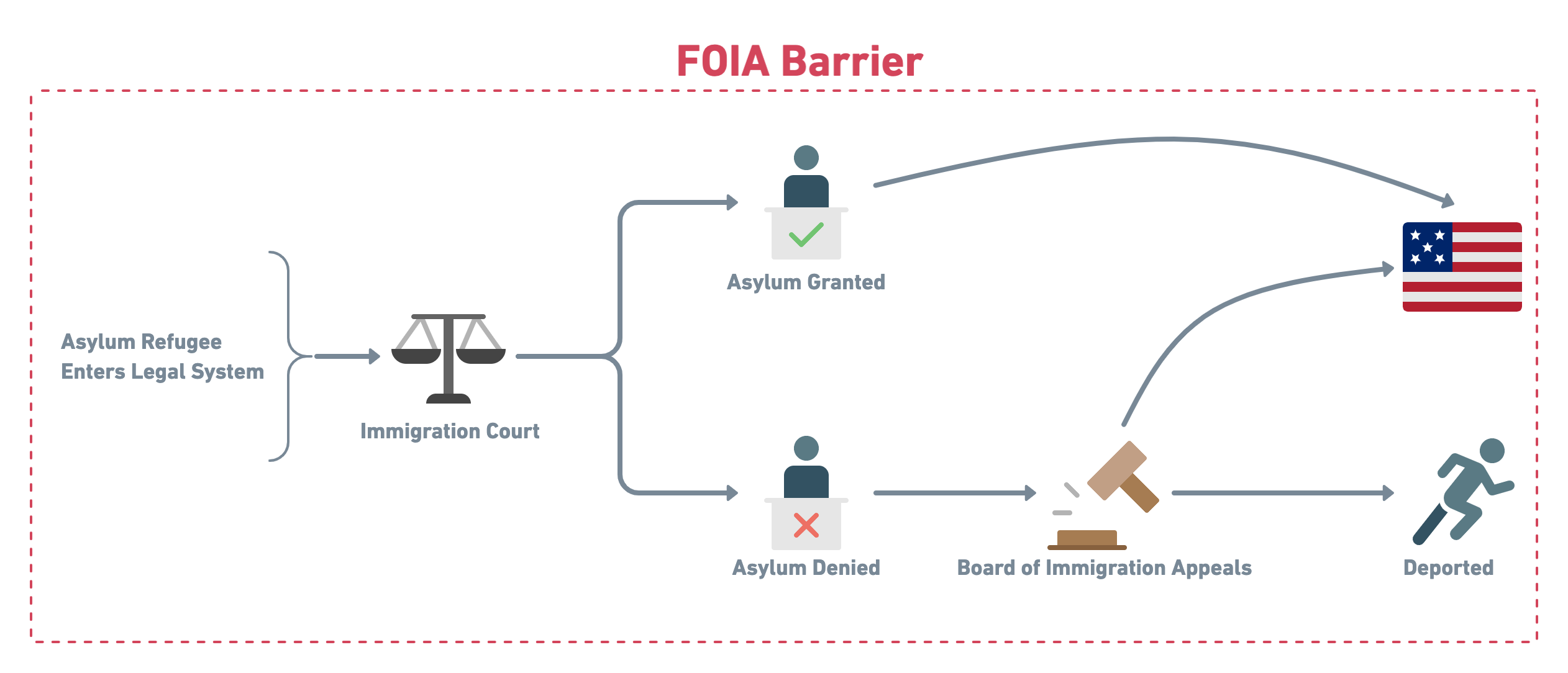
Our goal as a large diverse team was to create a product that facilitated the gathering of the siloed immigration court documents into one location. Our frontend compatriots crafted an elegant and informative user-experience to make uploading these documents easy and to ensure data integrity. The Data Science team was tasked with configuring an Optical Character Recognition (OCR) scraper to pre-populate the desired features for the user to update for accuracy.
As a Data Science team member and Design Liaison, I was tasked with improving sub-functions of the OCR component for more accurate feature extraction and coordinating with the frontend team.
Our OCR tool is composed of functions that work together to return a JSON object of select features. The JSON string is stored and display, allowing for user corrections. One of my goals was to improve the OCR's gender recognition component. The approach implemented before, counted the presence of gendered pronouns for the entire document. While this approach was a good start; a deeper dive into the legal documents uncovered possible flaws. What if the documents referenced a lawyer or judge? Words like 'the' if processed incorrectly by OCR could be output as 't' and 'he' producing a gendered pronoun from a stop word. This and other edge cases proved to be alluring challenges to tackle that will yield measurable increases in accuracy.
As mentioned before, the previous method to infer gender from the documents was by counting and comparing all encountered
pronouns. . .word, by word. Meaning, each token (word) in the document was observed and compared to a list of known
pronouns incrementing a counter variable and returning the text from the greater count. Below is the original approach:
Improvements can be made from this approach. For starters, processing each word returned and conducting that comparison is not performant. Additionally, the edge cases mentioned above (subject of the pronoun, and incorrect OCR output) can be factored into a solution.
My first approach was to analyze the document by sentence, eliminating the need for word-by-word comparison and maintain some context. Taking this step also had the effect of solving an edge case issue of discerning the subject of the pronoun. With a full sentence under analysis, the next requirement is discovering a pattern of speech that the court uses to refer to the asylum seeker. Upon reviewing multiple court documents from the AWS S3 bucket a pattern emerged, the court would refer to the refugee with a common word: 'Respondent'. Within the sentence, the court would shorthand the term with a gendered pronoun; perfect! With that target keyword, I implemented spaCy's PhraseMatcher to package other keywords, and added a label 'RESP' for text tagging. Using a for-loop and spaCy's sentence recognizer, I filter sentences with the keyword and add to a string for later processing. Invoking part of speech (POS) tagging, the function counts tagged--'PRON'--words and checks against a known list; if present in the list, the count for the respective gender is incremented. Once the end of the document is reached, the values are compared, and the largest value outputs the string (just like before).
Before implementation, the accuracy was low, but the count had variability and always output an answer. Testing the new approach yielded more accurate results and suffered in precision if the selected text lacked any triggering keywords. Of the categorized results, roughly 60% was correctly identified versus the initial implementation approached 30% correct identifications.
To increase the precision of the function, capturing the neighboring sentences of the keyword/phrase may increase the
possibility of triggering a count and reducing the amount of unknown results. In reviewing the case documents, I noticed a
previously overlooked edge case: refugees with dependents or a family. This edge case brings the topic-specific function
aptly named get_gender a more general use or another feature to extract altogether; detect multiple refugees
in the documents.
It was a pleasure to work on a project with such impact to people and families from across the world. As a first generation American whose parent immigrated from Cuba during the political strife; this project provided me a window into helping those like my own family. The technical challenges of Natural Language Processing and using the tools in a more in depth use case unlocked an exciting tangent in Data Science I am excited to trek. As much of the codebase was well established and expansive; wading into, learning and pin-pointing areas for development is analogus to the experience I expect to encounter on the next project/company I work for. In my previous programming experiences, I have started projects from the ground up, this project provided me experience in working with a large team on a large codebase. As a result of this project, I have also improved my skills in communicating with a large team, and coordinating fixes and solutions to the problems with others.
Predict visual inspection outcome by modeling cutting toolpaths from a CNC mill.


Extracting actionable data from Immigration Court documents using OCR and Python.